过去几年,AI 芯片行业有一个很有意思的现象,很多公司最初讲的故事,和后来真正活下来的原因,并不完全一致。
5月14日,Cerebras以每股185美元定价,募资约55.5亿美元,对应市值398.17亿美元。成为2026年迄今全球规模最大的IPO。上市首日暴涨70%。
他讲的故事是:一颗刷新世界纪录的大芯片、一份超过200亿美元的OpenAI 合同、一个超过两亿美金的GAAP净利润。
但如果把 Cerebras 的故事拆分成两层:一层是技术与产品的真实位置,一层是IPO招股书里写在白纸黑字上的另一面,这个故事可能会给资本市场留下更多的未完待续。
业内一直对Cerebras的Wafer-Scale存在着质疑,在硬件上主要围绕工程实现和良率展开的。
WSE涉及的版图设计、片上互联、缺陷绕行、PVT 一致性、散热、供电、封装,每一项都是工程上的硬骨头。客观地说,Cerebras把这些骨头啃下来了,这本身就是一项很强的工程成果,确实是实现了工程意义上的突破。
在良率上,Cerebras 对外宣称做到了 100%。可如果仔细研究其S1文件和公开的信息和资料,它实际上只是改变了良率本身的计算方式。
传统芯片的良率算的是一颗die是否如预期完整可用,只要落上一个致命缺陷,整颗芯片就会被报废或降级出售。Cerebras把良率的定义换了一种计算方式:整片晶圆能否通过冗余核心和片上网络绕过缺陷,最终凑出一个逻辑上完整的计算系统。根据S-1文件的描述:这是从 memory 行业借来的思路,DRAM/SRAM实际上就是靠冗余Row/column 把良率做到接近100%,Cerebras 也把这套做法搬到逻辑芯片上。
这倒不能说他完全是在偷换良率的概念,真要实现如此大面积上的系统可用性也很不容易。靠着片内互连和结构上的取巧,Cerebras实现了某种工程上的突破和产品层面的平衡。但说到底,它和传统 GPU 良率口径不在同一个度量衡里,并不能直接横向比较。
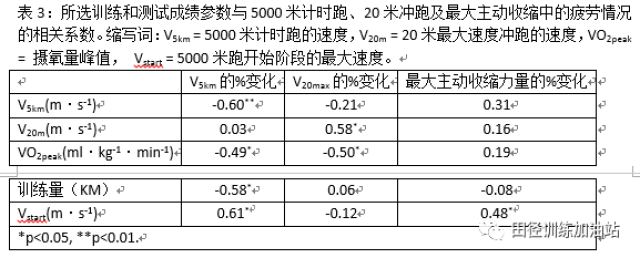
从Cerebras的视角来看,除了WSE, 还有一个显著特点,也是其多次强调的创新突破之处,那就是片内带宽极高。根据其公开说法,片上 NoC 带宽达到Pbps量级。
但如果仔细研究就会发现,只要数据需要离开晶圆,还是要面对其他 AI芯片面临的问题,片(卡)间带宽的瓶颈同样会出现,片内和片间互连的量级差大约在 100 倍以上。
训练市场有三个绕不过去的约束。硬件:大模型训练拼的不是单芯片算力,是外部内存与外部互连,权重、梯度、optimizer state、activation 都要在大规模系统里高效搬运,而WSE恰恰在片外 I/O 互连上是短板。
软件:Nvidia 的真正壁垒在 GPU+CUDA+NCCL+NVLink+NVSwitch+HBM+服务器+云厂商部署+开发者生态共同搭出的整套系统,这种壁垒不是单点技术领先就能撼动。训练场景的客户基本上主要为全球大模型的头部玩家了,他们当下最大的战略任务是“留在牌桌上、争最快迭代”,没有人会用如此巨大的机会成本去赌一颗非Nvidia的训练芯片。
Cerebras当年为训练配了SwarmX和MemoryX,这其实一定程度上是借用了AMD的既有成果,挂在 WSE外面解决内存与扩展。但实际部署中这套配套基本没被认真用起来,根源还是那句话,WSE 的技术亮点在片内,AI 系统的真实瓶颈在系统,在模型如此规模化的今天,片间与片外的瓶颈,直接限制了系统的效能,进一步限制了应用场景。
它还押过一个更大的赌注:非结构化权重稀疏,理论上 8:1 任意稀疏可以拿到接近 8 倍的有效算力,在产品定义与设计上,要在AI计算的泛化意义上来实现,那是非常难的。但在实际上,大模型最后没走这条路,业界主流是 MoE、低精度量化(FP8/FP4/MXFP)、attention 优化。Cerebras 在硬件上尝试去做一个很难的特性,但这个特性没有成为模型演进的主路线。
这也再次证明,AI芯片产品经理要对AI模型有很深刻的理解和预判能力,不然的话,产品定义和设计,就会面临极高的风险。
推理和训练的系统约束完全不同,推理和场景有关,其计算模式可以解耦。Cerebras 把推理任务做成一条流水线:把整个大模型按层切成几段,分别放到一片或多片 WSE 上;推理时数据像在工厂传送带上一样,从第一片 WSE 流到下一片,每片只负责自己那一段计算。
这套办法之所以能在 WSE 上跑通,关键在于一个细节,串接片与片之间需要传输的,只是这一步算出来的中间结果(activation),数据量相对较小;而真正吃内存的部分(模型权重、用户对话过程中累积的 KV cache)则被锁在每一片 WSE内部,不需要反复跨片搬运。
这恰好绕开了 WSE 最大的短板,片外 I/O 不够快(只是相对于片间来说,和其他 AI芯片其实也在同一个数量级上)。对追求高 token 吞吐的推理场景,这条路线的工程意义是真实的:Cerebras Inference在公开 benchmark上跑出了比主流GPU方案快约15倍的token速度。
模型大小、结构、KV cache 需求差异极大,再加上 SRAM 容量、片外 I/O 这些底层约束,WSE 只能在“特定模型 + 特定适配”的场景下打出最强表现。它的最优市场策略,就应该是找到最通用的模型、量最大的HyperScaler客户,针对其计算系统进行软硬件的适配与优化,这也就意味着,从经济意义上来看,它必须挑客户。
到这里,技术故事讲完了。一颗工程上有真本事的大芯片,从训练市场退了出来,在推理市场找到了一条高吞吐路径,但这条路径必须靠少数大客户和深度适配才能走通。
2026 年 1 月,Cerebras 公开宣布与 OpenAI 的多年合同,金额“超过 200 亿美元”,部署 750MW 高速 AI 推理算力,双方共同设计未来模型与硬件。这是 Cerebras IPO路演中很重的一句线文件中,这句话却成为了一组互相咬合的合同条款,需要拼起来才能看到全貌。
把这三件事放在一起看,OpenAI与Cerebras之间走的是一个完整的资金闭环:
这是一笔以“算力期权 + 股权认购权”打包的交易,被会计准则切成三张表,但商业实质是同一笔生意。
也就是说,Cerebras 2025 年报告口径里的所有收入与毛利率,都还没有扣过 OpenAI 这笔账。
全部OpenAI Warrant按授予日公允价值约27.4亿美元计算,其中约15.4亿美元对应已归属及被公司判断为probable的部分,将自2026年一季度起随OpenAI收入确认节奏冲减收入;剩余约12亿美元则主要取决于OpenAI是否行使额外容量选择权及后续交付进度。
今年2月24日,AMD与Meta达成了一项为期五年、总规模超千亿美元的战略合作,根据协议,Meta将在未来五年内部署6GW算力规模的AMD GPU集群。作为对价,AMD向Meta授予最多1.6亿股、约占总股本10%的业绩型认股权证,行权价仅为每股0.01美元的象征性水平。
再看毛利率,从2024年的42.3%降到2025年的39.0%,其在MD&A里提到云业务占比上升,与数据中心成本相关的项目也稀释了毛利,与此同时,未来还将出现客户认股权证冲减收入。换句线%的毛利率,毛的有点毛骨悚然:上市后,OpenAI 和AWS的认股权证所带来的的影响一旦从 2026 年 Q1 开始确认,毛利率算起来就更低了。
S-1中附注的Note 5里明确写到:G42和MBZUAI在ASC 850下被认定为相互的关联方。也就是说,Cerebras在2024和2025两年里,几乎全部收入都来自一组在会计上可以视为“同一客户阵营”的阿布扎比实体。应收账款来看集中度更夸张——2024 年末G42占91%的应收账款,2025 年末MBZUAI占 77.9%。
从整个客户组合来看:2025年86%的收入来自一个相互关联的阿联酋客户组合,剩余约 14% 是其他长尾客户,OpenAI在2025年财报里还没有真正开始确认收入。Cerebras 当下的产品需求被锁在一个非常窄的客户面里,而向前看,IPO 之后的收入故事高度依赖 OpenAI——而 OpenAI 这个故事,又必须用Warrant 当作配套条件才成立。
这就是一家在上市前投资份额被疯抢的明星AI芯片公司的真实技术、产品、客户、营收和利润状况!
Wafer-Scale Engine算是过去十年最有辨识度的AI芯片项目,后期重新定位的“超高速推理”作为产品定位也跑出了市场——OpenAI 的 Codex-Spark 模型在 2026 年 2 月已经跑在了Cerebras上对外服务。在Nvidia锁死训练侧、推理侧仍存在多种架构机会的当下,在全球资本市场为AI产业疯狂砸钱的当下,Cerebras选择此时上市,也是煞费苦心。
但如果在二级市场真金地白银投票,还是要在这些故事之外,仔细研究几个非常具体的问题。
问号三:客户结构能不能从“主权 AI 项目承包商”切换为“AI推理基础设施公司”?2024–2025 两年 86%–85% 的收入来自互为关联方的 G42 + MBZUAI 组合,收入集中度太高。这种集中度在传统工业品业务里可以被解释为“早期单点突破”,但对一家标榜为世界顶级AI芯片公司来说,它意味着估值锚是不稳定的。OpenAI 的引入能否在2026–2027年真正稀释这种集中度,要看后续的实际收入分布——而不是合同金额和市场叙事。
问号四:WSE-4 能不能补齐架构层面的短板?当前 WSE-3 有三个工程缺口:缺乏 FP8 / MXFP / FP4 等低精度浮点支持、片外和片间互连的带宽极度不足等远不够支撑大模型 KV Cache、以及其核心粒度太小给编译器和数据映射带来高复杂度。Cerebras 自己也承认推理经济性高度依赖片上 SRAM。如果 WSE-4 不完成数量级别的改善,超高速推理的故事就不那么完备。产品层面客观地说,在芯片硬件既定的情况下,软件无法进行数量级别地优化系统能力,毛利率的改善必须靠硬件架构层面实打实地获取!
问号五:这套“认股权证(Warrant)换订单”的模式,二级市场愿不愿意买单?Meta 接受过 AMD 的Warrant,AWS也拿了Cerebras的Warrant,OpenAI 拿了Cerebras 更激进的Warrant,国内已上市和正在IPO的几家AI芯片公司也在用各自版本的客户股权激励换订单。
这种模式它能不能每次都跑成功,且一直可以跑下去,我们需要拭目以待。这次Cerebras的IPO,会是这个模式在国际资本二级市场上进行的压力测试。