本案例以《Spark+Kafka构建实时分析Dashboard案例介绍》为基础,且在之前已有一个2017年的版本《Spark大数据分析案例之平均心率检测》,但由于该版所使用的Kafka、Spark版本较旧,现着手推出以Spark3.2.0、Kafka2.6.0为基础的实时分析Dashboard案例(即2022版)。
该案例涉及模拟数据生成,数据预处理、消息队列发送和接收消息、数据实时处理、数据实时推送和实时展示等数据处理全流程,所涉及的各种典型操作涵盖Linux、Spark、Kafka、JAVA、MySQL、Ajax、Html、Css、Js、Maven等系统和软件的安装和使用方法。通过本案例,将有助于综合运用大数据课程知识以及各种工具软件,实现数据全流程操作。
如果你的计算机上已经安装了Hadoop,本步骤可以略过。如果没有安装Hadoop,请访问Hadoop3.1.3安装教程_单机/伪分布式配置_Hadoop3.1.3/Ubuntu18.04(16.04),依照教程学习安装即可。注意,在这个Hadoop安装教程中,就包含了Ubuntu环境安装、Java的安装,所以,按照这个教程,就可以完成Ubuntu、JDK和Hadoop这三者的安装。
如果你的计算机上已经安装了Spark与Maven,本步骤可以略过。如果没有安装,请访问
Spark2.1.0入门:Spark的安装与使用,依照本教程学习安装即可。
1. 上述教程所安装版本为Spark2.1.0非本次案例所用版本,我们只需将Spark2.1.0换成Spark3.2.0即可,只需替换压缩包,安装方法不变。Spark3.2.0压缩包可以点击这里到百度云盘下载(提取码:ziyu)
2. Spark3.2.0自带Scala2.12,所以无需再安装Scala,Maven的安装位于上述教程的最后部分,请各位记得往下翻。
如果你的计算机上已经安装了Kafka2.6.0,本步骤可以略过。如果安装的版本较老,请先删除旧版本sudo rm -rf /usr/local/kafka #你的Kafka路径,然后访问Kafka的安装和简单案例测试。注意上述教程所安装的Kafka版本非本案例所用版本,请访问Kafka2.6.0官方下载页面。
如果你的计算机上已经安装了MySQL,本步骤可以略过。如果没有安装,请访问Ubuntu安装MySQL及常用操作,注意,Ubuntu 18.04安装MySQL时,可能不需要你设置密码,,所以在登录数据库时会出现Mysql:ERROR 1698 (28000): Access denied for user ,点击此处查看解决方法。(ps:请记住你设置的密码)
点击这里从百度网盘下载spark-homework压缩包,这是本案例的代码。下载后输入下列命令。
我们将工程目录打包至/usr/local/spark/sparkcode下,方便操作,以下是工程目录
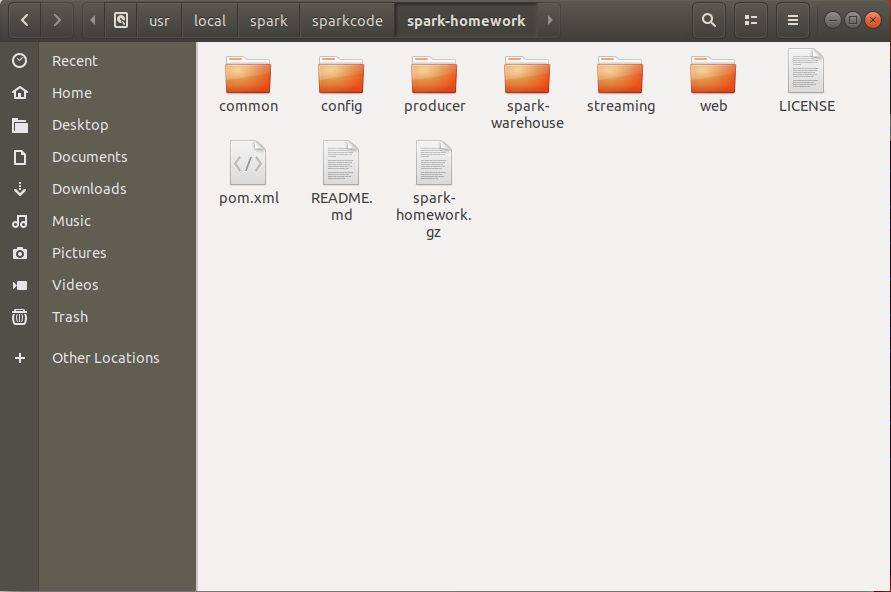
1. common目录存放的是整个项目所公有的类。其中程序文件夹中包含beans, config, db和utils。Beans中存放实体类,config中存放相关配置的类,db中配置数据库的连接等,utils中存放产生Json的工具类等。
2. config目录存放的是整个项目的配置参数,比如kafka生产者的地址和端口号、数据库的配置,如账户名,密码等。Web浏览器访问的地址和端口号等。
4. streaming目录存放的是对kafka数据操作并写入数据库的相关文件;
5. web目录存放的含有对http响应的相关处理和资源文件。如js,css,html文件。
本案例采用的数据集是由应用程序producer随机产生的。该数据集表示的正常人的心跳速率。下面列出产生的数据格式定义:
这个案例实时检测平均心率,因此针对每条记录,我们只需要获取name和rate即可,然后发送给Kafka,接下来Spark Streaming再接收进行处理,将其写入MySQL数据库。Web通过间隔若干时间查询某个时间段内的心跳,并对其进行可视化。
上述代码很简单,首先通过随机产生RecordBean实体,然后通过Json工具进行序列化,接着每隔sleep秒发送给kafka。
MetricsResource.java文件负责连接数据库并从数据库中读取数据,该文件内容如下:
上述文件通过定义字符串类型的sql的查询语句,从数据库中读取相关的数据。
上述代码中function定义了一个数据结构用来存放从MySQL中读取的数据、实时更新数据并展示。
通过streaming操作kafka获取数据后,将数据写入MySQL数据库。我们可以使用如下代码创建数据库和表。
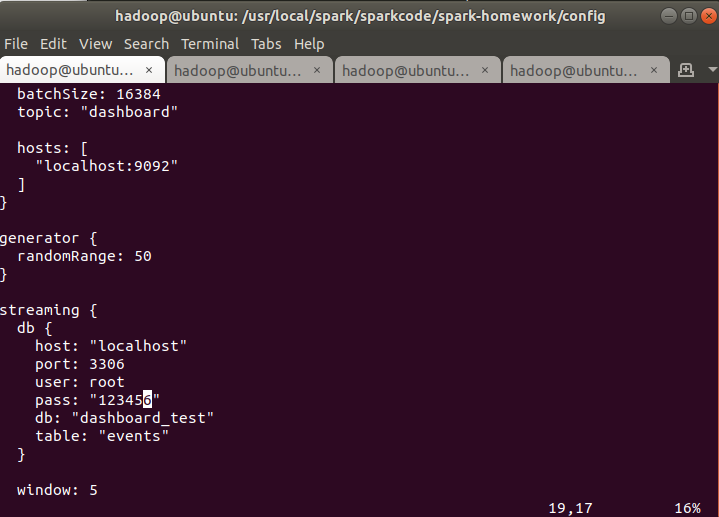
注意:此处的user一般为root,密码为你登录MySQL用户root的密码,我这里设置的时“123456”,请更改为你自己的密码,其他地方无需变化。
此处由于需要下载maven的包,所需时间较长,切记不可退出,在等待的时候,不妨站起身来活动一下筋骨^^
开启spark streaming 服务并且它会从kafka主题中处理数据到MySQL。重新开启一个终端,前面的终端千万不要关闭。
开启kafka producer,并且它会将事件写入kafka主题中。重新开启一个终端,前面的终端千万不要关闭。
开启web服务器,如此可以观察dashboard。重新开启一个终端,前面的终端千万不要关闭。输入以下代码
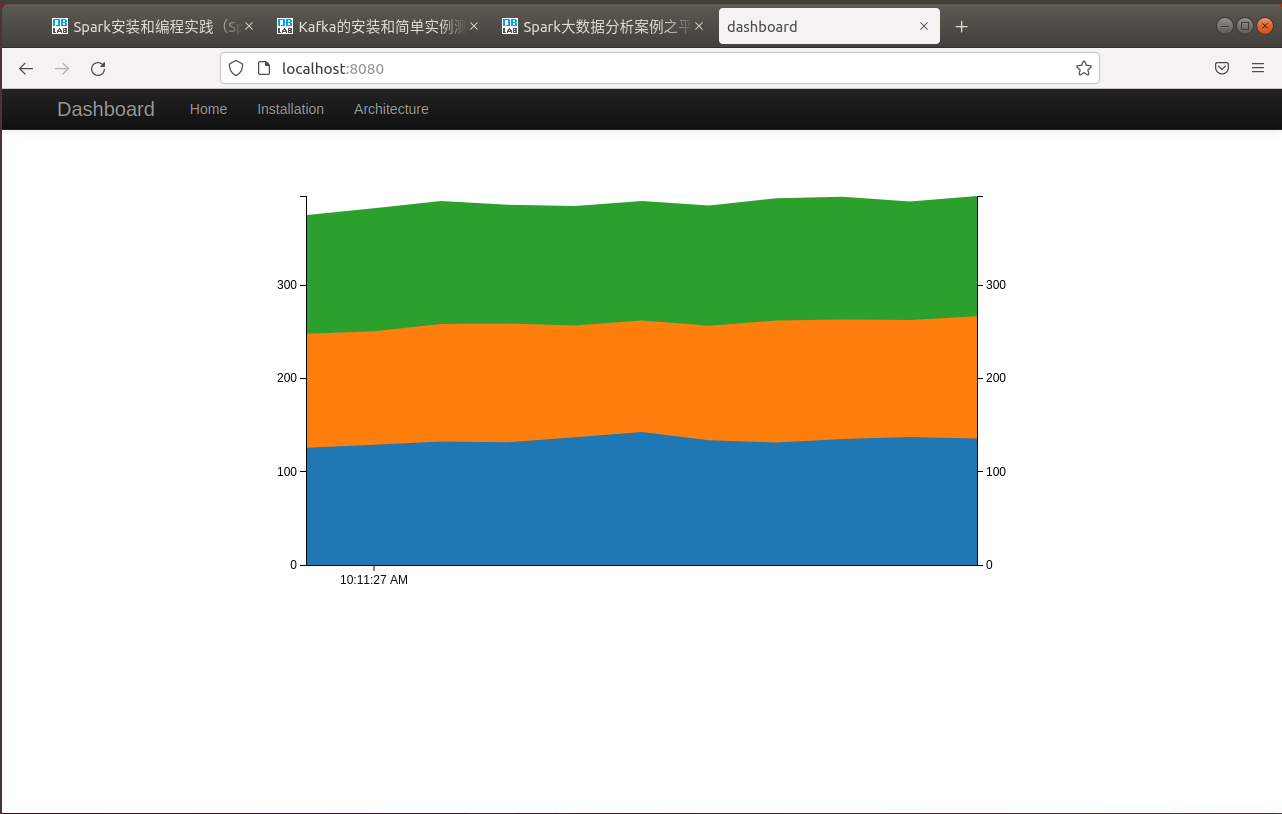
最后在浏览器中输入进行浏览结果。三种颜色分别代表三个人,他们在不同时刻的平均心率。
问题解析:在网页读取数据库内容时,是用Ubuntu系统的时间去与数据库中的时间进行配对,在工程代码中我们使用的是GMT+8,即国区时间,但是安装Ubuntu18.04时,系统自动使用美区时间,导致系统时间与数据库时间不匹配。